什么是协议
词条解释:经过谈判、协商而制定的共同承认、共同遵守的规定与条款。
标准协议:买票上车,司机与乘客都认同协议,只要乘客买了票,司机必须让乘客上车。
流氓协议:生米煮成熟饭。
什么是Http协议
Http协议是Hyper Text Transfer Protocol(超文本传输协议)的缩写,是用于从万维网(WWW)服务器传输超文本到本地浏览器的传送协议。
客户端与服务端都是认同的,简单一点理解就是客户端找服务端要东西,也就是请求,服务端必须给客户端东西,也就是响应。
在浏览器端输入域名,会发生什么
发生了什么:
搜索本地Dns > 本地host > 向宽带运营商服务器发起Dns解析请求 > 建立TCP连接(三次握手) > 数据传输 > TCP连接断开(也就是挥手)
什么是Dns
Dns是domain name service的缩写,它的作用是将域名翻译成ip地址。服务器或者应用,对于域名是无感知的,它们只会IP地址查找网络节点,Dns其实就是一个翻译,将服务器看不懂的域名地址翻译成Ip地址,这样用户在浏览器中输入域名,服务器就可以通过dns知道用户请求的是哪个网站,然后才将对应的网站内容返回给用户。
Dns找不到的情况下会从本地host中查找;
chrome查看本地Dns缓存 chrome://net-internals/#dns
Http协议分为三部分,Http状态行、Http请求头,Http响应
Http状态行
必应的: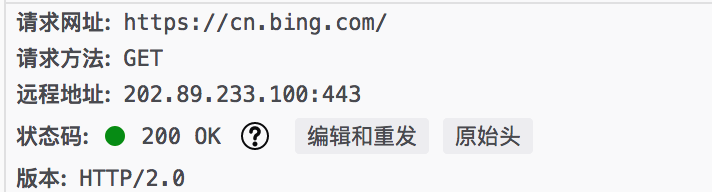
百度的: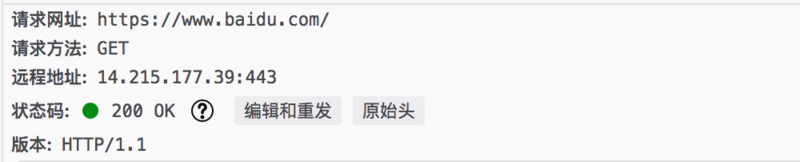
上面的图片是firefox的,chrome的长这样
状态行由包含了请求方式,请求路径,协议版本等数据构成
常见属性:

Request URL:请求Url
Request Method: 请求方式,除了常用的GET、POST外还有PUT与DELETE
Status Code: 常用的状态码有如下几种
1xx 信息处理状态码
表示数据正在处理中
2xx 成功状态码
* 200:数据被正常处理
* 204: 服务器接受数据并请求成功处理,但没有资源可返回
3xx 重定向状态码
* 302:临时性重定向
* 301:永久重定向,与302的区别是对于SEO更加友好,搜索引擎到页面后爬虫会记录重定向的地址
* 304:重定向到本地缓存,浏览器中存在访问页面时会用到
4xx 客户端错误
* 400:错误的请求,比如本地开发nginx配置错误后,访问某个本地站点返回400
* 403:服务端收到了请求,但拒绝访问,比如普通员工请求管理员数据提示403
* 404:找不到该路径对应的资源
5xx 服务端错误
* 500:服务器端执行请求时发生错误
* 503:服务器处于超负载或者正在停机维护,现在无法处理请求
当然Http状态码包含六七十种,具体可以看W3C关于状态码的规范)
Remote Address: 请求远程Ip地址
Referrer Policy: Referrer策略,当我们在页面中请求图片、Js、接口的时候浏览器一般会加上表示来源的Reffer数据,该数据有5个值。
* no-referrer: 所有情况下都不发送referrer
* no-referrer-when-downgrade: 协议降级时不发送 Referrer 信息,比如Https页面中请求http资源,大部分浏览器默认所采用的
* Origin Only: 发送只包含host部分的Reffer信息,比如“101.101.0.3/main的referrer”值就是“101.101.0.3”
* origin-when-crossorigin: 只有跨域是才发送只包含host部分的reffer值,(域名,协议,端口其中任何一个值不一致则被认为是跨域)
* unsafe-url: 无论任何情况下都发送reffer信息,很少使用
Http请求头
包含3部分,请求行、请求首部、请求体。
请求行

类似于上图的一串数据,默认为空
请求首部

请求首部就是客户端向服务器提供的额外信息,比如User-Agent表明客户端身份,表明客户端的身份,常见的请求首部如下:
- Accept: 告知服务端客户端接受的MIME类型数据,比如“text/html,image/jpeg”表示接受“html”文本与“jpeg”格式图片文件
- Accept-Charset: 浏览器接受字符集类型,默认“utf-8”,很多中文网页中是“gb2312”
- Accept-Encoding: 浏览器能解压数据的解码方式,常见的有“gzip、deflate、 br”,存在多个的情况下使用逗号隔开,在浏览器支持的情况下优先使用后置解压方式,如“gzip,deflate,br”三个中优先使用br解码
- Connection: 连接方式,默认“Keep-Alive”,表示需要持续连接,但此处的持续连接指的并不是永久连接,而是指在一定时间内如果存在数据请求则会复用通一个Tcp容器传输数据,否则断开
- Content-Length: 设置请求正文长度,对于Post请求无效
- Scheme: 使用协议,默认Http/Https,默认Http
- Host:浏览器请求的主机与端口,与Scheme配合可以在服务端进行第三方接口转发代理
- User-Agent:浏览器信息,可以用来进行获取访问浏览器类型占比分析。“GOOGLEBOT-IMAGE”是google的图片爬虫User-Agent信息,可以用来分析网页图片被爬虫抓取次数。
- Content-Type: 内容格式,比如“text/html”表示html文本,“Application/json”表示传输json数据。
- Cache-control: 缓存控制,这里不做细讲,详细原理可以看这篇博文
请求体

Get类型的请求请求内容是有长度限制的,比如IE中限制是2KB,Post中无限制。
Http响应
HTTP响应是服务器在接收客户端发送请求后经过一些处理而做出的响应,Http响应与Http请求类似,也由三个部分组成,分别是:状态行,响应头,响应正文
状态行
与Http请求状态行一致,不深究
响应头

响应头就是服务端想客户端提供的额外信息,常见的响应头如下:
- Connection: 连接方式,默认“Keep-Alive”,如果服务端不支持长连接方式则会返回close
- Content-Type: 内容格式,比如“text/html”表示html文本,“Application/json”表示传输json数据。
- Set-Cookie: 设置cookie数据,包含cookie主体内容,过期时间,作用域等信息
- …很多数据与Http请求头一致,数据在来回传递
响应正文
与Http请求正文一致,区别是数据由服务度发送给客户端
会话跟踪
由于Http协议是一个无状态协议,该协议不能保存客户信息,一旦数据传输完毕,下次数据请求需要重新连接,所以需要会话跟踪
Cookie
简单一点理解就是Cookie是服务端颁发给客户端的一个通行证,用来确认客户信息,浏览器得到这个通行证后,会在本地保存起来,当浏览器再次请求该网站是,浏览器将这个通行证一并提交给服务器,服务器检查该通行证,一次来确认用户信息。
Cookie在请求头和响应头之间来回传递,所以客户端与服务端都能获取到Cookie数据。
Session
在不理解Http协议是一个无状态协议的情况下,初学者往往会有一个误区,认为Session是保存在服务端的,当服务端与客户端连接关闭的时候Session会被清空。
正确的理解应该是Session其实是一个特殊的Cookie。
- 当服务端需要未客户客户端的请求创建一个Session的时候,首先会检查客户端是否存在sessionId标识,存在SessionId的情况下,则说明以前已经为此客户端创建过Session,服务器就按照SessionId把这个Session检索出来使用。
- 客户端不存在SessionId的情况下,服务端会新建一个Session,并且生成一个与该Session相关联的SessionId,SessionId一般都是经过加密计算,很难找到规律的字符串,
- 这个session id将被在本次响应中返回给客户端保存。
- 客户端保持SessionId的方式仍然是采用Cookie进行保存,这样在交互过程中浏览器可以自动的按照规则把这个标识发挥给服务器。
- 般这个cookie的名字都是类似于“SEEESIONID”,而。例如:xxxSESSIONID=KI98uvjFDJu671F7C2HmdnV6QZcEbzWoWiBYEnLerjQ99zWKjHb!-135785664。
- 当服务端在设置的时间段内没有与客户端进行Session数据的传输情况下,会自动清除服务端Session对象。
举个例子:
上图在koaJs中添加session
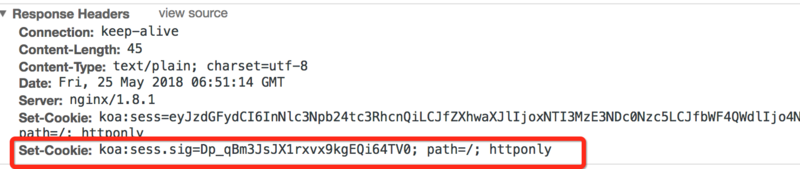
上图是服务端返回的cookie,这个cookie与一般的cookie的区别是是带一串session标识加密字符串(koa:sess.sig=Dp_qBm3JsJX1rxvx9kgEQi64TV0)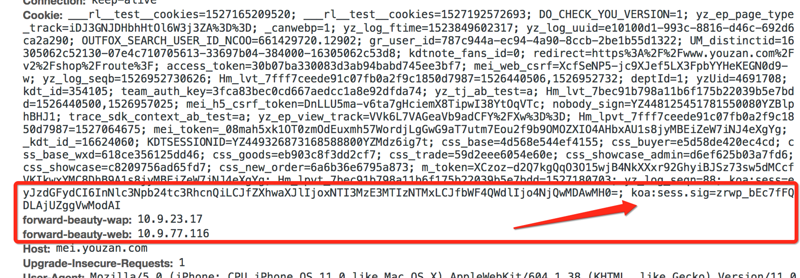
上图是客户端发送的cookie,与一般的cookie的区别也是呆了一串session标识加密字符串
对比cookie:
- 如果浏览器禁用了Cookie,Session同样不可使用。
- 对比于Cookie,Session对于服务器消耗更大。
Http1.1缺点
目前大部分网站使用的都是Http1.1协议,Http1.1协议存在以下缺点
- Http1.1是文本协议,对与人类来说是很容易理解的,但对于计算力来说及其不友好,转换效率低
- Tcp启动与连接都很慢,虽然可以使用keep-alive复用Tcp链接(这也是为什么网页中的图片资源为什么需要使用精灵图的原因)。
- 当网页中资源较多的情况下,浏览器处于资源控制对于单个域名会有最多同时发起6-8个连接请求限制
- 统一域名下Http请求头重复
- 资源加载不能设置优先级
Http2
了解Http2一开始可能会有两个误区
- 很多教程中都把Https当做Http2来讲解,╯□╰,Https是针对网页数据加密传输的一种认证机制。
- Http2协议并不是Http2.0协议,后续官方把后面的版本叫做http3.0了,所以2就是2了,22222222~
Http2协议专门针对Http1.1协议缺点做了改进
二进制文本协议
HTTP/2 采用二进制格式传输数据,而非HTTP1.1 中的文本格式,对于计算机解析起来会更高效二进制协议解析起来更高效。
单一连接
在同一个域名下,Http2只会创建一个Tcp或者Tls连接,减少了连接数,对于多个资源的页面Http1.1中会创建6~8个连接。
并且由于Tcp的滑动连接(连接刚开始数据传输很慢,后续会越来越快),Http1.1中多个Tcp连接会导致每个资源的请求都相当慢,Http2中由于只创建一个连接,完美的避免了这种情形。
Http2中的这个连接可以承载任意数量的双向数据流。每个数据流都以消息的形式发送,而消息由个帧(HTTP2中数据通信的最小单位)组成。多个帧之间可以乱序发送,因为根据帧首部的流标识可以重新组装。
关于帧的格式(官方)如下:1
2
3
4
5
6
7
8
9+-----------------------------------------------+
| Length (24) |
+---------------+---------------+---------------+
| Type (8) | Flags (8) |
+-+-------------+---------------+-------------------------------+
|R| Stream Identifier (31) |
+=+=============================================================+
| Frame Payload (0...) ...
+---------------------------------------------------------------+
多路复用
多路复用是通过在一个流上分配多个HTTP请求响应交换来实现的。流在很大程度上是相互独立的,因此一个请求上的阻塞或终止并不会影响其他请求的处理。下图一目了然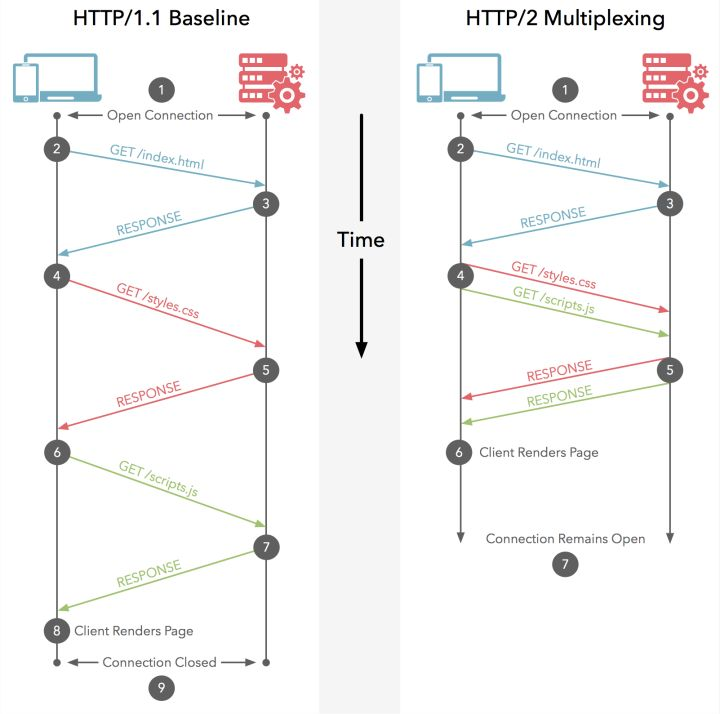
请求头优化
HTT2在客户端和服务器端使用“请求对照表”来跟踪和存储之前发送的请求头key-value,对于相同的数据,不再通过每次请求和响应发送;
在一定的时间内,在HTTP/2的连接存续期内始终存在,由客户端和服务器共同渐进地更新;
每个新的首部键-值对要么被追加到当前表的末尾,要么替换表中之前的值
并且Http2对请求头进行数据进行“HPACK”数据压缩,╯□╰说实话我也不知道这个是个什么鬼~
服务端推送
服务端可以在发送页面HTML时主动推送其它资源,而不用等到浏览器解析到相应位置,发起请求再响应。例如服务端可以主动把 JS 和 CSS 文件推送给客户端,而不需要客户端解析 HTML 再发送这些请求。
该如何开启,如何设置,好像没有比较好的教程~
资源传输优先级
资源传输设置优先级,比如优先加载js脚本,让页面尽快出现动态效果
怎么设置还没进行过研究~
参考资料
http状态码:https://www.w3.org/Protocols/rfc2616/rfc2616-sec10.html
浏览器缓存:https://segmentfault.com/a/1190000012233230
Session原理:https://zhuanlan.zhihu.com/p/33925382